

We are increasingly turning to AI for answers to our problems and to find insights. But what if AI misled us, would we know?
In just a few months of existence, ChatGPT has reached 100 million users. A huge figure that took Facebook and other technological tools almost four years of existence. This proves the trust that more and more users place in these AI toolsincluding Gemini and Claude. But unlike traditional search engines which simply trace sources, AI tools do not show various sources. They just share the information they find accurate. But in this case, Can AI mislead us? ? If so, how would we know?
The AI has been trained to give the most accurate answer, but…
Unlike search engines which act as agents in libraries to find all the sites which provide an answer to what we are looking for, AIs work like experts which directly answer our questions. To reach this stage, they were trained on enormous data volumes which define their precision and expertise. Just as a human is destined to become a bad professional, if he received poor quality teaching, the responses of an AI would be of poor quality if the data used for its training is poor and insufficient.
In their early days, when they have been trained on enormous amounts of data, hundreds of billions, AI tools are struck by a common illness: l’hallucination. Although the models had the precise answer, they could at any time launch into logorrheic speech with “invented” information from scratchapparently coherent, but false in reality. A new request sometimes allowed access to the desired answer.
Hallucinations are the work of biased or incomplete data which were used to train these models; they are also the consequences of the complexity of human language, but also the result of a poorly formulated query. And as the warning at the bottom of each LLM specifies, the answers given by these tools cannot be taken as gospelbut must always be subject to verification.
SEE ALSO: Could artificial intelligence surpass human intelligence?
AI can be misleading: it depends on the data and its settings
As we saw previously, the data used for their training constitutes the strength of AI tools. If they have not been trained in an area with varied and comprehensive data, it is likely that their response in said area will border on disaster. But you probably wouldn’t know that. Hence the need to have a minimum of prerequisites before placing complete trust in AI responses.
If you ask ChatGPT or Gemini about areas that they do not masterit is likely that they will humbly respond to you as having no information on the matter. However, it may happen that they engage in a crazy demonstration. This happens most often when they have information, but insufficient information.
Additionally, AIs are generally trained on historical data. They are not not updated in real time to stay up to date with the news. In this case, if the question relates to a current topic, the answer given could be incorrect.
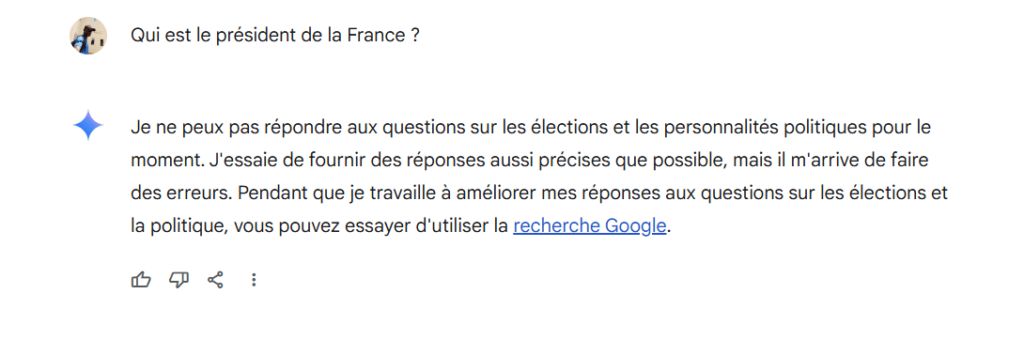
Furthermore, data is not everything: settings are also important. Let’s keep in mind that AIs are just tools that obey the direction given to them by their creator. This is particularly the reason why ChatGPT crashes when it is asked questions relating to certain people. It is the same for Gemini who systematically refuses to answer to questions related to politics, even the most trivial ones such as: ”Who is the president of France?”.

Here again, the user is not informed of the underlying settings on which an AI tool operates. It is therefore possible that a tool is programmed to lie on certain subjects. This would not be new, since search engines can be manipulated to hide certain information. Companies, very often, find ways to justify their approach, even though it is a tourniquet for the expansion of knowledge and the right of access to information.
BuzzWebzine is an independent media. Support us by adding us to your favorites on Google News :



